Multi label cross entropy loss function pdf
Package ‘MLmetrics’ May 13, 2016 Type Package Title Machine Learning Evaluation Metrics Version 1.1.1 Description A collection of evaluation metrics, including loss, score and
Computes the binary cross entropy (aka logistic loss) between the output and target. Parameters: output – the computed posterior probability for a variable to be 1 from the network (typ. a sigmoid )
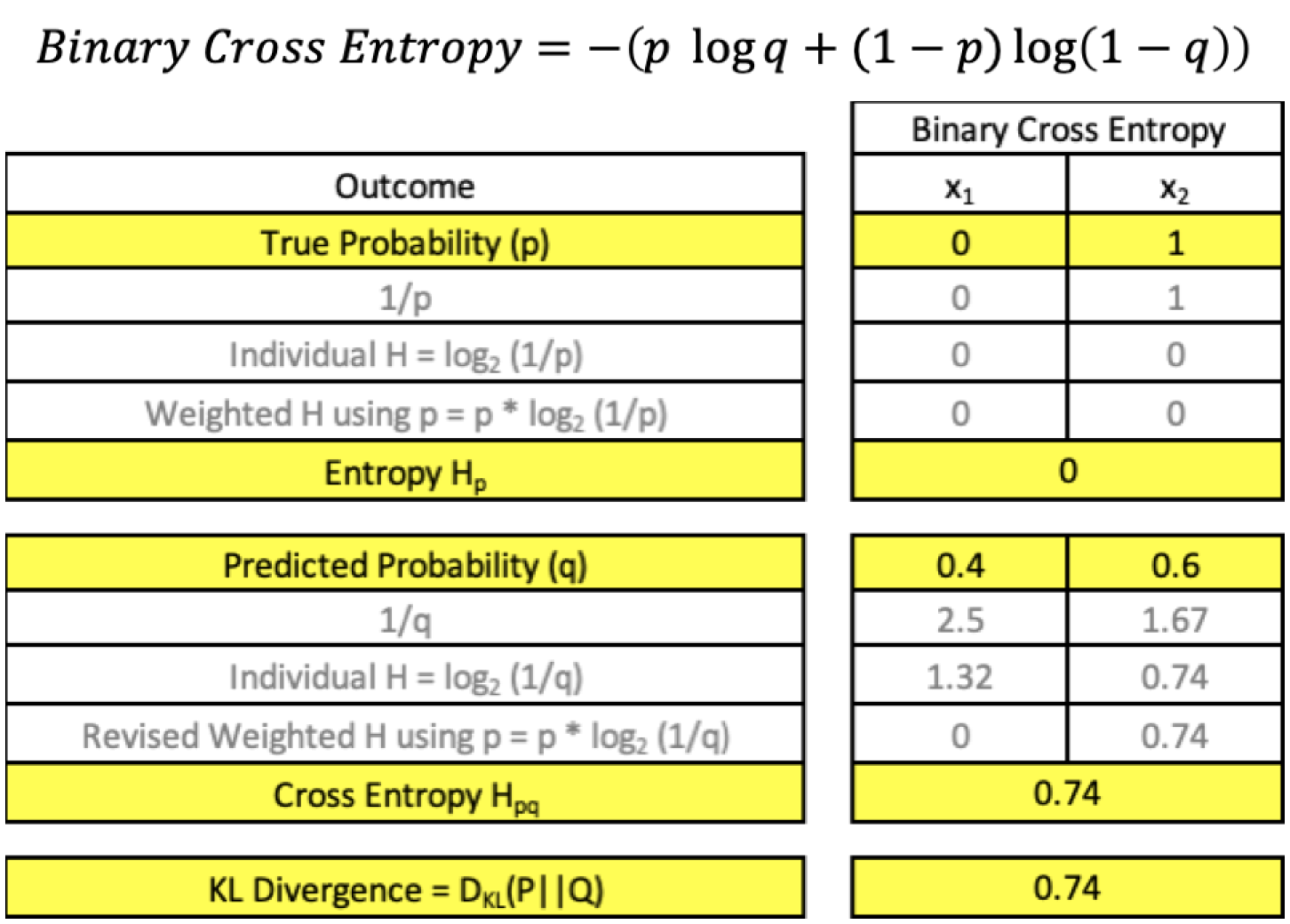
Binary Cross Entropy — Cross entropy quantifies the difference between two probability distribution. Our model predicts a model distribution of {p, 1-p} as we have a binary distribution. We use binary cross-entropy to compare this with the true distribution {y, 1-y}
Change relu to sigmoid of output layer. Modify cross entropy loss to explicit mathematical formula of sigmoid cross entropy loss (explicit loss was working in my case/version of tensorflow )
The proposed model is learned to minimize a combined loss function that was made by introducing a cross entropy loss to the lower layer of LSTM-based triplet network. We observed that the proposed
Classification and Loss Evaluation – Softmax and Cross Entropy Loss Lets dig a little deep into how we convert the output of our CNN into probability – Softmax; and the loss measure to guide our optimization – Cross Entropy.
Request PDF on ResearchGate On May 1, 2016, Fatemeh Farahnak-Ghazani and others published Multi-label classification with feature-aware implicit encoding and generalized cross-entropy loss
I read that for multi-class problems it is generally recommended to use softmax and categorical cross entropy as the loss function instead of mse and I understand more or less why. For my problem of multi-label it wouldn’t make sense to use softmax of course as each class probability should be independent from the other.
Cross entropy loss Notice that when actual label is 1 (y(i) = 1), second half of function disappears whereas in case actual label is 0 (y(i) = 0) first half is dropped off. In short, we are just multiplying the log of the actual predicted probability for the ground truth class.
Connection between cross entropy and likelihood for multi-class soft label classification 1 Difference between mathematical and Tensorflow implementation of Softmax Crossentropy with logit
Function to calculate the pixel-wise Wasserstein distance between the flattened prediction and the flattened labels (ground_truth) with respect to the distance matrix on the label space M. Parameters:
Binary Cross Entropy 49.75 ! 50.51 70.81 ! 71.32 48.09 ! 48.34 Table 1: 1-best accuracy, recall@5, and full accuracy for evaluation data using different loss functions (Random initialization ! …
Creates a cross-entropy loss using tf.nn.softmax_cross_entropy_with_logits_v2. weights acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value.
This is to convert the label range from [0,255] to [0,1] as per the requirement of the Sigmoid Cross Entropy Loss function. Depending on your multi-label loss function, the scaling parameter can be …
Multi-Class Classification Tutorial with the Keras Deep
Multi-class SVM Loss PyImageSearch
Loss function: Now that we are considering two discrete probability distributions and , a natural choice for the loss function is the cross-entropy loss function. The loss for a training example with predicted class distribution and correct class is
The categorical cross-entropy loss (negative log likelihood) is used when a probabilistic interpretation of the scores is desired. Let y = y1, . . . , yn be a vector representing the distribution over the labels 1, .
Ll is a simple multi-class cross-entropy loss function. Yt is defined as: 0 if the i-th disease is not found 1 otherwise for i — 1 14, and is the corresponding model prediction. IQ is a modified version of Ll where Yo is defined as: 0 if no finding from the input figure 1 otherwise and yo is the corresponding model prediction. With the label Yo, we expect the model to first reflect whether
We present a new loss function for multi-label classification, which is called label-wise cross-entropy (LWCE) loss. The LWCE loss splits the traditional cross-entropy loss into multiple one vs. all cross-entropy losses for
Multi-label Classification of Satellite Images with Deep Learning Daniel Gardner Stanford University dangard@stanford.edu David Nichols Stanford University
cross entropy loss and a weighted sigmoid cross entropy loss was applied on the output logits instead of a softmax cross entropy loss because an image could have multiple la-
neurons in the output layer is the same as that of labels, with binary cross-entropy loss. Adopting such structure means constructing a learning network for multi-task, and enabling different labels to share the CNNs in the bottom layer while improving the performance of small-scaled labels. B. Data Augmentation We follow the practice in [8, 9]. Performed random cropping and horizontal flip on
Loss functions for classification. Plot of various functions. Blue is the 0–1 indicator function. Green is the square loss function. Purple is the hinge loss function. Yellow is the logistic loss function. Note that all surrogates give a loss penalty of 1 for y=f(x= 0) In machine learning and mathematical optimization, loss functions for classification are computationally feasible loss
employing a multi-label cross-entropy loss function, in which each pixel is classified to both the foreground class and background according to the predicted probabilities
Softmax Classifiers Explained. While hinge loss is quite popular, you’re more likely to run into cross-entropy loss and Softmax classifiers in the context of Deep …
cross-entropy loss to a multi-class scenario: Let there be K classes, with class labels The multi-class cross entropy loss can be written using indicator function I(.): Similarly, the multi-class generalization of the sigmoid function is the softmax function. The multi-class predictive distribution becomes: Multi-class cross-entropy loss and softmax 5 Here are the outputs of a neural network
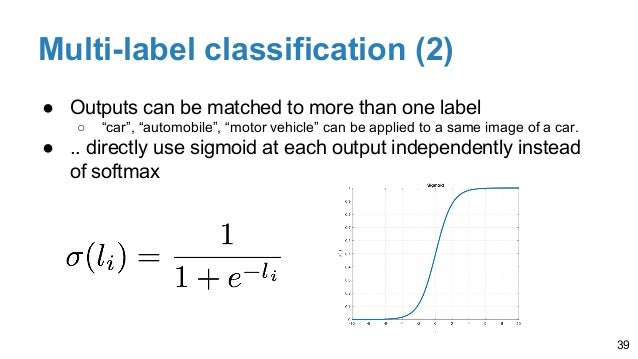
In multi-label (as opposed to multi-class) classification, an input can have more than one label, or maybe none at all. We have one sigmoid output for each label and we minimize the (binary) cross-entropy for each label (each label is Bernoulli) and we sum over these for all labels.
We propose a novel multi-label cross-entropy loss function to train the network based on multiple localization maps. Each pixel adaptively contributes to each class according to the predicted weights embedded in the localization map.
Multinomial probabilities / multi-class classification : multinomial logistic loss / cross entropy loss / log loss It is a problem where we have k classes or categories, and only one valid for each example.
Multi-class multi-label classification. For multi-label multi-class classification problems, that is, when each sample can have many correct answers, the sigmoid function is often used at the output layer of the neural network models (without applying softmax).
C17 – Cross entropy method for multiclass support vector machine – Budi Santosa 101 ISSN 2085-1944 entropy method.. The basic idea of the CE method
JD AI Fashion Challenge-Fashion style Technical Report
Introduction¶ When we develop a model for probabilistic classification, we aim to map the model’s inputs to probabilistic predictions, and we often train our model by incrementally adjusting the model’s parameters so that our predictions get closer and closer to ground-truth probabilities.
a single logistic output unit and the cross-entropy loss function (as opposed to, for example, the sum-of-squared loss function). With this combination, the output prediction is always between zero
Cross entropy can be used to define a loss function in machine learning and optimization. The true probability p i {displaystyle p_{i}} is the true label, and the given distribution q i {displaystyle q_{i}} is the predicted value of the current model.
For the first strategy, a novel multi-label cross-entropy loss is proposed to train the network by directly using multiple localization maps for all classes, where each pixel con- …
Cross-entropy loss explanation. Ask Question 17. 18. Suppose I build a NN for classification. The last layer is a Dense layer with softmax activation. I have five different classes to classify. Suppose for a single training example, the true label is [1 0 0 0 0] while the predictions be [0.1 0.5 0.1 0.1 0.2]. How would I calculate the cross entropy loss for this example? machine-learning deep
class label assumed to be in the range {1,2,…,K}. 3.1. Multi-task Training In multi-task training with two tasks, let L(1) n (W) and L(2) n (W) be loss functions for the two tasks, defined similar to Eq. 1. We use a multi-task loss function of the form: Ln (W)= γ (1) n)+(1−) (2) n (2) where 0 ≤γ≤1. 3.2. Class-weighted cross-entropy In the case of KW spotting, the amount of data – instep pathfinder tag along bike manual Log loss, aka logistic loss or cross-entropy loss. This is the loss function used in (multinomial) logistic regression and extensions of it such as neural networks, defined as the negative log-likelihood of the true labels given a probabilistic classifier’s predictions. The log loss is only
Another variant on the cross entropy loss for multi-class classification also adds the other predicted class scores to the loss: The second term in the inner sum essentially inverts our labels and score assignments: it gives the other predicted classes a probability of , and penalizes them by the of that amount (here, denotes the th score, which is the th element of ).
Derivative of softmax: The Softmax function and its derivative Derivative of a softmax based cross-entropy loss : Backpropagation with Softmax / Cross Entropy Backpropagation : I collected a list of tutorials, from simple to complex, BackPropagati…
Cross-entropy loss, or log loss, measures the performance of a classification model whose output is a probability value between 0 and 1. Cross-entropy loss increases as the predicted probability diverges from the actual label. So predicting a probability of .012 when the actual observation label is 1 would be bad and result in a high loss value. A perfect model would have a log loss of 0.
The full cross-entropy loss that involves the softmax function might look scary if you’re seeing it for the first time but it is relatively easy to motivate. Information theory view . The cross-entropy between a “true” distribution (p) and an estimated distribution (q) is defined as:
where any value outside the original input image region are considered zero ( i.e. we pad zero values around the border of the image). Since input is 4-D, each input[b, i, j, :] is a vector.
tor and the loss function considers all the attributes jointly. Different from the loss function in DeepSAR, the sigmoid cross entropy loss, which is defined in Formula 3, is intro-
Categorical cross-entropy is the most common training criterion (loss function) for single-class classification, where y encodes a categorical label as a one-hot vector. Another use is as a loss function for probability distribution regression, where y is a target distribution that p shall match.
machine learning The cross-entropy error function in
Cross-entropy is one of the many loss functions used in Deep Learning (another popular one being SVM hinge loss). Definition Cross-Entropy measures the performance of a classification model whose output is a probability value between 0 and 1.
Keras is a Python library for deep learning that wraps the efficient numerical libraries Theano and TensorFlow. In this tutorial, you will discover how you can use Keras to develop and evaluate neural network models for multi-class classification problems.
Logarithmic loss (related to cross-entropy) measures the performance of a classification model where the prediction input is a probability value between 0 and 1.
To make this work in keras we need to compile the model. An important choice to make is the loss function. We use the binary_crossentropy loss and not the usual in multi-class classification used categorical_crossentropy loss.
cross-entropy and Kullback-Leibler (KL) loss are employed as optimization function for the classification and distribu- tion learning, respectively. By combining the two losses, our framework learns both distribution prediction and classifica-tion tasks at the same time. During the end-to-end training process, these two tasks can boost each other providing a ro-bust representation for text
I am currently using the following loss function: loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits, labels)) However, my loss quickly approaches zero since there are ~1000 classes and only a handful of ones for any example (see attached image) and the algorithm is simply learning to predict almost entirely zeroes.
A pdf writeup with answers to all the parts of the problem and your plots. Include in the pdf a copy of your code for each section. In your submission to bCourses,include: 2. A zip archive containing your code for each part of the problem, and a README with instructions on how to run your code. Please include the pdf writeup in this zip archive as well. Submitting to Kaggle 3. Submit a csv
classifier trained with one-versus-all minimizing the cross-entropy loss function, but other linear classifiers such as the support vector machine (SVM) can also be used [5].
The Cross-Entropy Method for Optimization Zdravko I. Botev, Department of Computer Science and Operations Research, Universit´e de Montr´eal, Montr´eal Qu´ebec H3C 3J7, Canada.
Learning Acoustic Frame Labeling for Speech Recognition

Losses Keras Documentation
The Hamming loss (HamLoss) computes the percentage of labels that are misclassi ed in a multi-label classi cation, i.e., relevant labels that are not predicted or irrelevant labels that are predicted [8].
Note: when using the categorical_crossentropy loss, your targets should be in categorical format (e.g. if you have 10 classes, the target for each sample should be a 10-dimensional vector that is all-zeros except for a 1 at the index corresponding to the class of the sample).
In this Facebook work they claim that, despite being counter-intuitive, Categorical Cross-Entropy loss, or Softmax loss worked better than Binary Cross-Entropy loss in their multi-label …
To learn more about your first loss function, Multi-class SVM loss, just keep reading. Multi-class SVM Loss At the most basic level, a loss function is simply used to quantify how “good” or “bad” a given predictor is at classifying the input data points in a dataset.
trained by weighted cross entropy loss function to predict the test set label,the F2-score and threshold curve changes gently,so the F2-score is insensitive to threshold changes around around
This operation computes the cross entropy between the target_vector and the softmax of the output_vector. The elements of target_vector have to be non-negative and should sum to 1. The output_vector can contain any values.
GitHub sukritshankar/Caffe-LMDBCreation-MultiLabel
Cross Entropy Kartikey Pandey
In the softmax regression setting, we are interested in multi-class classification (as opposed to only binary classification), and so the label y can take on k different values, rather than only two. Thus, in our training set , we now have that .
Cross Entropy loss is a more advanced loss function that uses the natural logarithm (log e). This helps in speeding up the training for neural networks in comparison to the quadratic loss. This helps in speeding up the training for neural networks in comparison to the quadratic loss.
I figured the standard loss function for such problem is the sigmoid cross entropy (as opposed to the softmax cross entropy, which would only be appropriate for single class problems). For example, in TensorFlow one would use sigmoid_cross_entropy_with_logits .
LEARNING ACOUSTIC FRAME LABELING FOR SPEECH RECOGNITION WITH RECURRENT NEURAL NETWORKS Has¸im Sak, Andrew Senior, Kanishka Rao, Ozan Irsoy, Alex Graves, Franc¸oise Beaufays, Johan Schalkwyk
The Cross-Entropy Method for Optimization
Neural networks produce multiple outputs in multiclass classification problems. However, they do not have ability to produce exact outputs, they can only produce continuous results. We would apply some additional steps to transform continuos results to exact classification results.
propose a new sequence-to-sequence framework to directly decode multiple label sequences from a single speech sequence by unifying source separation and speech recognition functions in …

What error function is used in neural networks for a multi
niftynet.layer.loss_segmentation module — NiftyNet 0.4.0
– ASKING FOR A SECOND OPINION RE-QUERYING OF NOISY MULTI
Loss functions and metrics Cognitive Toolkit – CNTK

About loss functions regularization and joint losses
Improving multi-label loss function Cross Validated
About loss functions regularization and joint losses
Improving multi-label loss function Cross Validated
The full cross-entropy loss that involves the softmax function might look scary if you’re seeing it for the first time but it is relatively easy to motivate. Information theory view . The cross-entropy between a “true” distribution (p) and an estimated distribution (q) is defined as:
Request PDF on ResearchGate On May 1, 2016, Fatemeh Farahnak-Ghazani and others published Multi-label classification with feature-aware implicit encoding and generalized cross-entropy loss
Loss function: Now that we are considering two discrete probability distributions and , a natural choice for the loss function is the cross-entropy loss function. The loss for a training example with predicted class distribution and correct class is
Computes the binary cross entropy (aka logistic loss) between the output and target. Parameters: output – the computed posterior probability for a variable to be 1 from the network (typ. a sigmoid )
A pdf writeup with answers to all the parts of the problem and your plots. Include in the pdf a copy of your code for each section. In your submission to bCourses,include: 2. A zip archive containing your code for each part of the problem, and a README with instructions on how to run your code. Please include the pdf writeup in this zip archive as well. Submitting to Kaggle 3. Submit a csv
Loss functions for classification. Plot of various functions. Blue is the 0–1 indicator function. Green is the square loss function. Purple is the hinge loss function. Yellow is the logistic loss function. Note that all surrogates give a loss penalty of 1 for y=f(x= 0) In machine learning and mathematical optimization, loss functions for classification are computationally feasible loss
We present a new loss function for multi-label classification, which is called label-wise cross-entropy (LWCE) loss. The LWCE loss splits the traditional cross-entropy loss into multiple one vs. all cross-entropy losses for
This is to convert the label range from [0,255] to [0,1] as per the requirement of the Sigmoid Cross Entropy Loss function. Depending on your multi-label loss function, the scaling parameter can be …
cross-entropy loss to a multi-class scenario: Let there be K classes, with class labels The multi-class cross entropy loss can be written using indicator function I(.): Similarly, the multi-class generalization of the sigmoid function is the softmax function. The multi-class predictive distribution becomes: Multi-class cross-entropy loss and softmax 5 Here are the outputs of a neural network
I figured the standard loss function for such problem is the sigmoid cross entropy (as opposed to the softmax cross entropy, which would only be appropriate for single class problems). For example, in TensorFlow one would use sigmoid_cross_entropy_with_logits .
Function to calculate the pixel-wise Wasserstein distance between the flattened prediction and the flattened labels (ground_truth) with respect to the distance matrix on the label space M. Parameters:
To learn more about your first loss function, Multi-class SVM loss, just keep reading. Multi-class SVM Loss At the most basic level, a loss function is simply used to quantify how “good” or “bad” a given predictor is at classifying the input data points in a dataset.
class label assumed to be in the range {1,2,…,K}. 3.1. Multi-task Training In multi-task training with two tasks, let L(1) n (W) and L(2) n (W) be loss functions for the two tasks, defined similar to Eq. 1. We use a multi-task loss function of the form: Ln (W)= γ (1) n) (1−) (2) n (2) where 0 ≤γ≤1. 3.2. Class-weighted cross-entropy In the case of KW spotting, the amount of data
The full cross-entropy loss that involves the softmax function might look scary if you’re seeing it for the first time but it is relatively easy to motivate. Information theory view . The cross-entropy between a “true” distribution (p) and an estimated distribution (q) is defined as:
python Multilabel Text Classification using TensorFlow
cross-entropy loss to a multi-class scenario: Let there be K classes, with class labels The multi-class cross entropy loss can be written using indicator function I(.): Similarly, the multi-class generalization of the sigmoid function is the softmax function. The multi-class predictive distribution becomes: Multi-class cross-entropy loss and softmax 5 Here are the outputs of a neural network
Loss Functions — ML Cheatsheet documentation
Loss functions for classification Wikipedia
C17 – Cross entropy method for multiclass support vector machine – Budi Santosa 101 ISSN 2085-1944 entropy method.. The basic idea of the CE method
What loss function for multi-class multi-label
Picking Loss Functions A comparison between MSE Cross
Cross Entropy loss is a more advanced loss function that uses the natural logarithm (log e). This helps in speeding up the training for neural networks in comparison to the quadratic loss. This helps in speeding up the training for neural networks in comparison to the quadratic loss.
Softmax Classifiers Explained PyImageSearch
We present a new loss function for multi-label classification, which is called label-wise cross-entropy (LWCE) loss. The LWCE loss splits the traditional cross-entropy loss into multiple one vs. all cross-entropy losses for
A Gentle Introduction to Cross-Entropy Loss Function
Softmax Classifiers Explained. While hinge loss is quite popular, you’re more likely to run into cross-entropy loss and Softmax classifiers in the context of Deep …
Improving multi-label loss function Cross Validated
IRIT & MISA at Image CLEF 2017 Multi label classi cation
Ll is a simple multi-class cross-entropy loss function. Yt is defined as: 0 if the i-th disease is not found 1 otherwise for i — 1 14, and is the corresponding model prediction. IQ is a modified version of Ll where Yo is defined as: 0 if no finding from the input figure 1 otherwise and yo is the corresponding model prediction. With the label Yo, we expect the model to first reflect whether
DeepNotes Deep Learning Demystified
CROSS ENTROPY METHOD FOR MULTICLASS SUPPORT VECTOR MACHINE
Binary Cross Entropy 49.75 ! 50.51 70.81 ! 71.32 48.09 ! 48.34 Table 1: 1-best accuracy, recall@5, and full accuracy for evaluation data using different loss functions (Random initialization ! …
Loss Functions for Computer Vision Models Playment Data
DeepNotes Deep Learning Demystified
How to do backpropogation of softmax loss function Quora
Note: when using the categorical_crossentropy loss, your targets should be in categorical format (e.g. if you have 10 classes, the target for each sample should be a 10-dimensional vector that is all-zeros except for a 1 at the index corresponding to the class of the sample).
Loss Functions for Computer Vision Models Playment Data
CROSS ENTROPY METHOD FOR MULTICLASS SUPPORT VECTOR MACHINE
Understanding Categorical Cross-Entropy Loss Binary Cross
Neural networks produce multiple outputs in multiclass classification problems. However, they do not have ability to produce exact outputs, they can only produce continuous results. We would apply some additional steps to transform continuos results to exact classification results.
A Purely End-to-end System for Multi-speaker Speech
A Gentle Introduction to Cross-Entropy Loss Function
Function to calculate the pixel-wise Wasserstein distance between the flattened prediction and the flattened labels (ground_truth) with respect to the distance matrix on the label space M. Parameters:
JD AI Fashion Challenge-Fashion style Technical Report
sklearn.metrics.log_loss — scikit-learn 0.20.2 documentation
cntk.losses package Microsoft Docs
employing a multi-label cross-entropy loss function, in which each pixel is classified to both the foreground class and background according to the predicted probabilities
Learning to segment with image-level annotations
About loss functions regularization and joint losses
Loss functions and metrics Cognitive Toolkit – CNTK
To make this work in keras we need to compile the model. An important choice to make is the loss function. We use the binary_crossentropy loss and not the usual in multi-class classification used categorical_crossentropy loss.
About loss functions regularization and joint losses
propose a new sequence-to-sequence framework to directly decode multiple label sequences from a single speech sequence by unifying source separation and speech recognition functions in …
Guide to multi-class multi-label classification with
Loss functions for classification Wikipedia
What loss function for multi-class multi-label
I read that for multi-class problems it is generally recommended to use softmax and categorical cross entropy as the loss function instead of mse and I understand more or less why. For my problem of multi-label it wouldn’t make sense to use softmax of course as each class probability should be independent from the other.
Multi-attribute Learning for Pedestrian Attribute
Categorical cross-entropy is the most common training criterion (loss function) for single-class classification, where y encodes a categorical label as a one-hot vector. Another use is as a loss function for probability distribution regression, where y is a target distribution that p shall match.
Alternative Loss Functions for Multi Label Classification
Neural networks produce multiple outputs in multiclass classification problems. However, they do not have ability to produce exact outputs, they can only produce continuous results. We would apply some additional steps to transform continuos results to exact classification results.
machine learning The cross-entropy error function in
CS189 Introduction to Machine Learning
Neural networks produce multiple outputs in multiclass classification problems. However, they do not have ability to produce exact outputs, they can only produce continuous results. We would apply some additional steps to transform continuos results to exact classification results.
Cross Entropy Loss (Log Loss) Deep Learning Course Wiki
Softmax Regression Ufldl
C17 – Cross entropy method for multiclass support vector machine – Budi Santosa 101 ISSN 2085-1944 entropy method.. The basic idea of the CE method
The Cross-Entropy Method for Optimization
A Friendly Introduction to Cross-Entropy Loss
Softmax Classifiers Explained PyImageSearch
propose a new sequence-to-sequence framework to directly decode multiple label sequences from a single speech sequence by unifying source separation and speech recognition functions in …
Package ‘MLmetrics’ The Comprehensive R Archive Network
Common Loss functions in machine learning – Towards Data
A Gentle Introduction to Cross-Entropy Loss Function
Classification and Loss Evaluation – Softmax and Cross Entropy Loss Lets dig a little deep into how we convert the output of our CNN into probability – Softmax; and the loss measure to guide our optimization – Cross Entropy.
Multi-label classification with feature-aware implicit
Multi-Task Learning and Weighted Cross-Entropy for DNN